.Researchers study which parts of the brain are engaged when a person evaluates a computer program
http://blog.naver.com/mssoms
http://jl0620.blogspot.com
http://jk0620.tripod.com
https://www.facebook.com/junggoo.lee.9
.Researchers study which parts of the brain are engaged when a person evaluates a computer program
연구자들은 사람이 컴퓨터 프로그램을 평가할 때 뇌의 어느 부분이 관여하는지 연구합니다

매사추세츠 공과 대학 Steve Nadis 신용: Pixabay/CC0 퍼블릭 도메인 DECEMBER 22, 2022
뇌 전체의 혈류 변화를 측정하는 기능적 자기 공명 영상(fMRI)은 "기능적 해부학"을 포함한 다양한 응용 분야에서 지난 수십 년 동안 사용되어 왔습니다. 사람은 특정 작업을 수행합니다. fMRI는 사람들이 수학 문제를 풀고, 외국어를 배우고, 체스를 두고, 피아노 즉흥 연주를 하고, 크로스워드 퍼즐을 하고, 심지어 "Curb Your Enthusiasm ." 거의 관심을 받지 못한 분야 중 하나는 컴퓨터 프로그래밍 입니다. 코드를 작성하는 잡일과 이미 작성된 코드를 이해하려고 노력하는 똑같이 혼란스러운 작업입니다. "컴퓨터 프로그램이 일상 생활에서 차지하는 중요성을 감안할 때"라고 Ph.D.인 Shashank Srikant는 말합니다.
MIT 컴퓨터 과학 및 인공 지능 연구실(CSAIL)의 학생은 "확실히 살펴볼 가치가 있습니다. 요즘 많은 사람들이 코드를 읽고, 쓰고, 디자인하고, 디버깅하고 있지만 코드를 읽을 때 머리에서 무슨 일이 일어나는지 아무도 모릅니다. 그런 일이." 다행스럽게도 그는 MIT 동료인 Benjamin Lipkin(Srikant와 함께 이 논문의 다른 주저자), Anna Ivanova, Evelina Fedorenko, Una-May O'Reilly와 함께 작성한 논문에서 그 방향으로 "진보"했습니다. 이달 초 뉴올리언스에서 열린 신경 정보 처리 시스템 컨퍼런스에서 발표되었습니다.
새로운 논문은 fMRI를 사용하여 프로그래머가 코드의 작은 조각 또는 스니펫을 "이해"할 때 두뇌를 모니터링하기 위해 동일한 저자가 작성한 2020년 연구 를 기반으로 작성되었습니다. (이 경우 이해는 스니펫을 보고 스니펫이 수행한 계산 결과를 올바르게 결정하는 것을 의미합니다.) 2020년 연구는 코드 이해가 언어 처리를 처리하는 뇌 영역 인 언어 시스템을 지속적으로 활성화하지 않는다는 것을 보여주었다고 뇌 및 인지 과학(BCS) 교수이자 이전 연구의 공동 저자인 Fedorenko는 설명합니다. "대신 일반적인 추론과 연결되어 수학적, 논리적 사고와 같은 영역을 지원하는 뇌 시스템인 다중 수요 네트워크가 강력하게 활성화되었습니다."
프로그래머의 MRI 스캔도 활용하는 현재 작업은 더 세분화된 정보를 얻기 위해 "더 깊이 파고들"고 있다고 그녀는 말합니다. 이전 연구가 평균적으로 코드를 이해하는 데 의존하는 뇌 시스템을 결정하기 위해 20~30명의 사람들을 조사한 반면, 새로운 연구는 컴퓨터 프로그램의 특정 요소를 처리할 때 개별 프로그래머의 뇌 활동을 조사합니다. 예를 들어 단어 조작을 포함하는 한 줄짜리 코드와 수학 연산을 수반하는 별도의 코드가 있다고 가정합니다. "우리가 뇌에서 보는 활동, 실제 뇌 신호에서 리버스 엔지니어링을 시도하고 특히 프로그래머가 보고 있는 것이 무엇인지 알아낼 수 있습니까?" Srikant가 묻습니다.
-"이것은 프로그램과 관련된 정보가 우리 뇌에 고유하게 인코딩되어 있음을 밝힐 것입니다." 그는 신경과학자에게 누군가의 뇌 신호를 보고 해당 속성을 추론할 수 있는 경우 물리적 속성이 "암호화"된 것으로 간주한다고 지적합니다. 예를 들어 루프(원하는 결과를 얻을 때까지 특정 작업을 반복하는 프로그램 내의 명령) 또는 컴퓨터가 한 작업에서 다른 작업으로 전환할 수 있는 다른 유형의 프로그래밍 명령인 분기를 생각해 보십시오. 관찰된 뇌 활동 패턴을 기반으로 그룹은 누군가 루프 또는 분기와 관련된 코드 조각을 평가하고 있는지 여부를 알 수 있습니다. 연구원들은 또한 코드가 단어 또는 수학 기호와 관련이 있는지, 누군가가 실제 코드를 읽고 있는지 또는 단순히 해당 코드에 대한 설명을 읽고 있는지 여부를 구분할 수 있었습니다.
-그것은 실제로 어떤 것이 암호화되어 있는지 여부에 대해 조사자가 물을 수 있는 첫 번째 질문을 해결했습니다. 대답이 '예'인 경우 다음 질문은 다음과 같습니다. 인코딩 위치는 어디입니까? 위에서 언급한 경우(루프 또는 분기, 단어 또는 수학, 코드 또는 이에 대한 설명)에서 뇌 활성화 수준은 언어 시스템과 다중 수요 네트워크 모두에서 비슷한 것으로 나타났습니다. 그러나 동적 분석이라고 하는 것과 관련된 코드 속성에 관해서는 눈에 띄는 차이가 관찰되었습니다. 프로그램은 시간이 지나도 변하지 않는 "정적" 속성(예: 시퀀스의 숫자 수)을 가질 수 있습니다.
-"그러나 프로그램은 루프가 실행되는 횟수와 같은 동적 측면도 가질 수 있습니다."라고 Srikant는 말합니다. "항상 코드를 읽을 수는 없고 해당 프로그램의 실행 시간을 미리 알 수는 없습니다." MIT 연구원들은 동적 분석의 경우 정보가 언어 처리 센터에서보다 다중 수요 네트워크에서 훨씬 더 잘 인코딩된다는 사실을 발견했습니다. 그 발견은 코드 이해가 뇌 전체에 어떻게 분포되어 있는지, 즉 어떤 부분이 관련되어 있고 어떤 부분이 해당 작업의 특정 측면에서 더 큰 역할을 하는지를 알아보기 위한 탐구의 한 단서였습니다.
팀은 컴퓨터 프로그램에서 특별히 훈련된 신경망이라는 기계 학습 모델을 통합한 두 번째 실험 세트를 수행했습니다. 이러한 모델은 최근 몇 년 동안 프로그래머가 코드 조각을 완성하는 데 성공적이었습니다. 이 그룹이 알아내고자 했던 것은 참가자들이 코드 조각을 검사할 때 연구에서 본 뇌 신호가 신경망이 동일한 코드 조각을 분석할 때 관찰된 활성화 패턴과 유사한지 여부였습니다. 그리고 그들이 도달한 대답은 자격이 있는 예였습니다. Srikant는 "신경망에 코드 조각을 넣으면 어떤 방식으로든 프로그램이 무엇에 관한 것인지 알려주는 숫자 목록이 생성됩니다."라고 말합니다.
컴퓨터 프로그램을 공부하는 사람들의 뇌 스캔은 유사하게 숫자 목록을 생성합니다. 예를 들어 프로그램이 분기에 의해 지배될 때 "두뇌 활동의 뚜렷한 패턴을 볼 수 있습니다"라고 그는 덧붙입니다. "기계 학습 모델이 동일한 스니펫을 이해하려고 시도할 때 유사한 패턴을 볼 수 있습니다." 막스 플랑크 소프트웨어 시스템 연구소의 마리야 토네바는 이와 같은 발견이 "특히 흥미진진합니다. 그들은 우리가 프로그램을 읽을 때 우리 뇌에서 일어나는 일을 더 잘 이해하기 위해 코드의 계산 모델을 사용할 가능성을 높인다"고 말합니다. MIT 과학자들은 그들이 밝혀낸 연결에 분명히 흥미를 느꼈습니다. 컴퓨터 프로그램 의 개별 조각 이 뇌에서 어떻게 인코딩되는지에 대한 빛을 비춰줍니다. 그러나 그들은 최근에 수집된 통찰력이 사람들이 실제 세계에서 어떻게 더 정교한 계획을 수행하는지에 대해 우리에게 무엇을 말해 줄 수 있는지 아직 알지 못합니다.
상영 시간 확인, 교통편 예약, 티켓 구매 등이 필요한 영화 보러 가기와 같은 이러한 종류의 작업을 완료하는 작업은 단일 코드 단위와 단일 알고리즘으로 처리할 수 없습니다. 그러한 계획을 성공적으로 실행하려면 "구성"이 필요합니다. 즉, 노래나 교향곡을 만들기 위해 개별 음악 마디를 조립하는 것과 같이 다양한 스니펫과 알고리즘을 합리적인 순서로 연결하여 새로운 것을 이끌어 내는 것입니다. CSAIL의 수석 연구 과학자인 O'Reilly 는 코드 구성 모델을 만드는 것은 "현재 우리가 이해할 수 없는 일"이라고 말합니다. Lipkin, BCS Ph.D. 학생은 "복잡한 프로그램을 구축하기 위해 간단한 작업을 결합하고 이러한 전략을 사용하여 일반적인 추론 작업을 효과적으로 처리하는 방법"을 알아내는 다음 논리적 단계라고 생각합니다. 그는 또한 팀이 지금까지 달성한 목표를 향한 진전 중 일부는 학제 간 구성 덕분이라고 믿습니다. "우리는 프로그램 분석 및 신경 신호 처리에 대한 개별 경험뿐만 아니라 기계 학습 및 자연어 처리에 대한 결합 작업을 활용할 수 있었습니다."라고 Lipkin은 말합니다. "신경과 및 컴퓨터 과학자들이 일반 지능을 이해하고 구축하기 위한 탐구에 힘을 합치면서 이러한 유형의 협력이 점점 보편화되고 있습니다." 추가 정보: 논문: 인간 및 인공 신경망에서 컴퓨터 프로그램의 수렴 표현 매사추세츠 공과대학 제공 이 이야기는 MIT 연구, 혁신 및 교육에 대한 뉴스를 다루는 인기 사이트 인 MIT News( web.mit.edu/newsoffice/ )의 호의로 다시 게시되었습니다.
https://techxplore.com/news/2022-12-brain-engaged-person.html
=========================
메모 2212230457 나의 사고실험 oms 스토리텔링
샘플c.oss.base.roof는 반복적으로 .osssys.피드백을 수행하면서 원하는 크기를 임의로 도달할 수 있다. 이들이 뇌의 혈류로 나타나면 일종에 뇌의 의식구조를 암시한다. 눈으로 보고 알아서 뇌에서 즉각적으로 판단하는 본능적인 반응들이 생물학적인 신경계를 지배한다면 일종에 샘플c.oss.base.roof의 생물학적 제한적 루프시스템이다.
만약에 이들이 인공지능화 된다면 물리적인 영역에서도 반응하는 뇌구조의 시스템이 될 것이고 시공간적인 크기를 가진다면 우주적인 거대구조 필라멘트 웹을 가진 샘플a.oms.sys가 나타난다. 허허.
Samplea.oms (standard)
b0acfd 0000e0
000ac0 f00bde
0c0fab 000e0d
e00d0c 0b0fa0
f000e0 b0dac0
d0f000 cae0b0
0b000f 0ead0c
0deb00 ac000f
ced0ba 00f000
a0b00e 0dc0f0
0ace00 df000b
0f00d0 e0bc0a
sampleb. qoms (standard)
0000000011=2,0
0000001100
0000001100
0000010010
0001100000
0101000000
0010010000
0100100000
2000000000
0010000001
sample b.poms (standard)
q0000000000
00q00000000
0000q000000
000000q0000
00000000q00
0000000000q
0q000000000
000q0000000
00000q00000
0000000q000
000000000q0
sample c.oss (standard)
zxdxybzyz
zxdzxezxz
xxbyyxzzx
zybzzfxzy
cadccbcdc
cdbdcbdbb
xzezxdyyx
zxezybzyy
bddbcbdca

-"This will reveal that information related to programs is uniquely encoded in our brains." He points out to neuroscientists that physical properties are considered "encoded" if you can infer those properties by looking at someone's brain signals. For example, think of loops (commands within a program that repeats certain actions until you get the desired result) or branches, which are other types of programming instructions that allow the computer to switch from one action to another. Based on the observed patterns of brain activity, the group could tell whether someone was evaluating a piece of code related to a loop or branch. Researchers were also able to tell if the code involved words or mathematical symbols and whether someone was reading the actual code or simply reading a description of that code.
-It actually addressed the first question an investigator might ask about whether something is encrypted or not. If the answer is yes, the next question is: Where is the encoding located? In the cases mentioned above (loops or branches, words or math, codes or descriptions of them), brain activation levels were found to be similar for both language systems and multidemand networks. However, notable differences were observed when it comes to code properties related to what is called dynamic analysis. Programs can have "static" properties that don't change over time, such as the number of digits in a sequence.
-"But programs can also have dynamic aspects, such as how many times a loop runs," says Srikant. "You can't always read code, and you can't know in advance how long that program will run." MIT researchers found that for dynamic analysis, information is encoded much better in multidemand networks than in language processing centers. The discovery was one clue in a quest to see how code comprehension is distributed throughout the brain, which parts are involved and which parts play a larger role in certain aspects of the task in question.
==========================
memo 2212230457 my thought experiment oms storytelling
The sample c.oss.base.roof can reach the desired size arbitrarily by repeatedly performing .osssys.feedback. When they appear in the bloodstream of the brain, they imply the structure of consciousness in the brain. If the instinctive reactions that are immediately judged by the eyes and the brain are governed by the biological nervous system, it is a kind of biological limiting loop system of the sample c.oss.base.roof.
If they are artificially intelligent, they will become a system of brain structure that responds even in the physical domain, and if they have a spatiotemporal size, a sample a.oms.sys with a cosmic macrostructure filament web appears. haha.
Samplea.oms (standard)
b0acfd 0000e0
000ac0 f00bde
0c0fab 000e0d
e00d0c 0b0fa0
f000e0 b0dac0
d0f000 cae0b0
0b000f 0ead0c
0deb00 ac000f
ced0ba 00f000
a0b00e 0dc0f0
0ace00 df000b
0f00d0 e0bc0a
sampleb. qoms (standard)
0000000011=2,0
0000001100
0000001100
0000010010
0001100000
0101000000
0010010000
0100100000
2000000000
0010000001
sample b.poms (standard)
q0000000000
00q00000000
0000q000000
000000q0000
00000000q00
0000000000q
0q000000000
000q0000000
00000q00000
0000000q000
000000000q0
sample c.oss (standard)
zxdxybzyz
zxdzxezxz
xxbyyxzzx
zybzzfxzy
cadccbcdc
cdbdcbdbb
xzezxdyyx
zxezybzyy
bddbcbdca

.New tool can assist with identifying carbohydrate-binding proteins
새로운 도구는 탄수화물 결합 단백질을 식별하는 데 도움이 될 수 있습니다
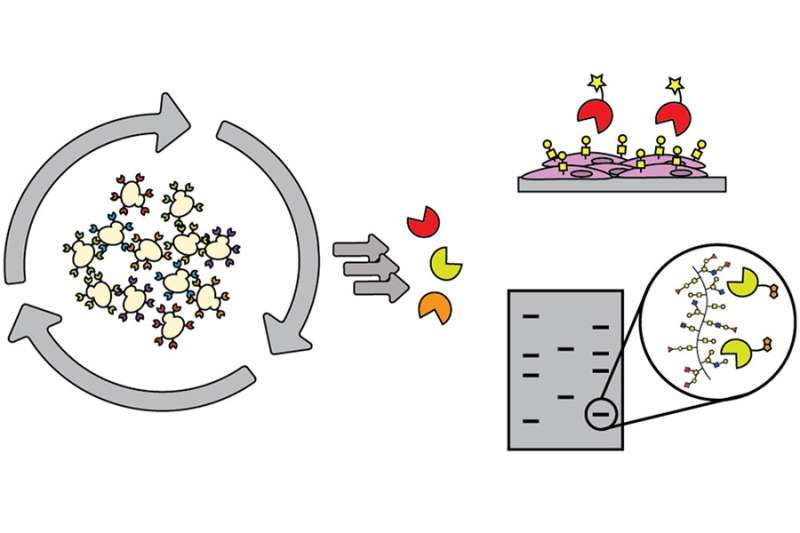
Danielle Randall Doughty, 매사추세츠 공과 대학 Imperiali Lab의 새로운 도구는 유도 진화를 사용하여 작고 초내열성 DNA 결합 단백질에서 글리칸 결합 단백질(GBP)을 생성합니다. 크레딧: 매사추세츠 DECEMBER 22, 2022
-공과대학 탄수화물에 대한 연구를 수행하는 사람들이 극복하기 위해 끊임없이 노력하고 있는 주요 장애물 중 하나는 설탕의 역할을 해독하는 데 사용할 수 있는 제한된 도구 모음입니다. 해결 방법으로 대부분의 연구자들은 식물이나 곰팡이에서 분리한 렉틴(당 결합 단백질)을 활용하지만, 렉틴은 크고 결합력이 약하며 특이성과 감지하는 당의 범위에 제한이 있습니다.
-ACS Chemical Biology 에 발표된 새로운 연구 에서 Barbara Imperiali 교수 그룹의 연구원들은 이 단점을 해결하기 위한 플랫폼을 개발했습니다. "탄수화물 고분자의 문제점은 생합성이 주형 기반이 아니라는 것입니다."라고 이 연구의 수석 저자이자 화학 및 생물학과의 교수인 Imperiali는 말했습니다. "생물학, 의학 및 생명공학은 단백질 및 핵산에 대한 기술 발전에 힘입어 발전해 왔습니다. 탄수화물 분야는 매우 뒤처져 있으며 필사적으로 도구를 찾고 있습니다." 탄수화물 결합 단백질 식별 생합성 탄수화물은 특정 효소에 의해 만들어지는 개별 당 분자 사이의 모든 연결이 필요하며 복잡한 탄수화물의 구조와 순서를 해독할 준비가 된 방법이 없습니다.
-탄수화물에 대한 항체를 생성할 수 있지만 그렇게 하는 것은 어렵고 비용이 많이 들며 연구에 실제로 필요한 것보다 훨씬 더 큰 분자를 생성합니다. 제한된 메커니즘에 시달리는 이 분야의 이상적인 자원은 결합체를 사용하여 구조를 결합하기 위해 탄수화물의 작은 덩어리를 인식하는 제한된 크기의 결합 단백질의 발견 또는 복잡한 구조 내에서 특정 탄수화물을 감지하고 식별하는 방법입니다.
이 연구의 저자는 탄수화물에 결합하는 능력이 전혀 없는 단백질에서 탄수화물 결합 단백질을 식별하기 위해 유도 진화와 영리한 스크린 디자인을 사용했습니다. 그들의 발견은 다양하고 프로그래밍 가능한 특이성을 가진 탄수화물 결합 단백질을 식별하기 위한 토대를 마련했습니다. 협업을 위한 간소화 이러한 발전을 통해 연구자들은 렉틴이 하는 일에 제한을 받거나 항체를 생성하는 능력에 의해 도전받지 않고 사용자 정의된 당 목표를 추적할 수 있습니다. 이러한 결과는 당생물학의 효모 표면 디스플레이 파이프라인의 효율성을 극대화하기 위해 엔지니어링 커뮤니티와의 향후 협력을 고무하는 데 도움이 될 수 있습니다. 있는 그대로, 이 파이프라인은 단백질에 대해 잘 작동하지만 당은 훨씬 더 어려운 표적이며 파이프라인을 수정해야 합니다.
미래의 응용 측면에서 이 혁신의 잠재력은 진단에서 장기적으로 치료에 이르기까지 다양하며 MIT 및 그 밖의 연구원과의 협력을 위한 길을 열어줍니다. 예를 들어, 화학 교수 Laura Kiessling의 연구 그룹은 독특하고 독특하며 배타적인 당으로 특이한 세포벽 구성을 가진 결핵균(Mtb)을 연구합니다. 이 방법을 사용하면 바인더가 잠재적으로 Mtb의 특정 기능으로 진화할 수 있습니다. 화학 공학 교수인 Hadley Sikes는 특정 에피토프 또는 마커에 대한 결합 파트너가 배치되는 종이 기반 진단 도구를 개발하고 이 발견을 사용하여 장기적으로 측면 흐름 분석 장치를 개발할 수 있습니다. 미래 솔루션을 위한 토대 마련 암에서 특정 당은 세포 표면에 과도하게 나타나므로 이론적으로 연구자들은 라벨링이 가능한 이 발견을 활용하여 진화된 글리칸 결합제에서 검출을 위한 도구를 개발할 수 있습니다. 이 발견은 또한 세포 이미징을 개선하는 데 크게 기여합니다. 연구원은 간단한 결찰 전략을 사용하여 형광단으로 바인더를 수정할 수 있으며 조직 또는 세포 이미징에 가장 적합한 형광단을 선택할 수 있습니다.
예를 들어, Kiessling 그룹 은 복잡한 미생물 혼합물을 조사하기 위해 형광 활성 세포 분류를 시작하기 위해 박테리아 당을 감지하기 위해 형광단으로 표시된 작은 단백질 바인더를 적용할 수 있습니다. 이것은 차례로 환자의 마이크로바이옴이 어떻게 교란되었는지 결정하는 데 사용될 수 있습니다. 또한 이러한 유형의 시약을 사용하여 지역 사회 내의 불균형을 판독하기 위해 환자의 입이나 상부 또는 하부 위장관의 미생물 군집을 스크리닝할 수 있는 잠재력이 있습니다. 더 먼 미래에 바인더는 잠재적으로 박테리아가 표시하는 당을 기반으로 특정 박테리아의 위장관이나 입을 청소하는 것과 같은 치료 목적을 가질 수 있습니다. 추가 정보: Elizabeth M. Ward 외, Thomsen-Friedenreich 항원 및 구조적으로 관련된 이당류 인식을 위한 조작된 글리칸 결합 단백질, ACS 화학 생물학 (2022). DOI: 10.1021/acschembio.2c00683 저널 정보: ACS 화학 생물학 매사추세츠 공과대학 제공 이 이야기는 MIT 연구, 혁신 및 교육에 대한 뉴스를 다루는 인기 사이트 인 MIT News( web.mit.edu/newsoffice/ )의 호의로 다시 게시되었습니다.
https://phys.org/news/2022-12-tool-carbohydrate-binding-proteins.html
==========================
메모 2212230530 나의 사고실험 oms 스토리텔링
나는 오랜동안 숫자더미 마방진을 연구하였다. 복잡한 배열들은 마ㅏ치 탄수화물을 만나는 것과 유사하다. 그러나 샘플a.oms와 샘플b.qoms을 발견하면서 결정적으로 숫자더미.물질더미의 세부적인 내용을 접할 수 있게 되었다.
그것이 제한된 메커니즘에 시달리는 이 분야의 이상적인 자원은 결합체가 되어 사용하여 구조로 여러단계로 결합하기 위해 탄수화물과 같은 배열의 작은 덩어리를 인식하는 제한된 크기의 결합 단백질.상수의 발견 또는 복잡한 구조 내에서 특정 탄수화물.배열페턴을 감지하고 식별하는 방법이 되었다. 허허.
Samplea.oms (standard)
b0acfd 0000e0
000ac0 f00bde
0c0fab 000e0d
e00d0c 0b0fa0
f000e0 b0dac0
d0f000 cae0b0
0b000f 0ead0c
0deb00 ac000f
ced0ba 00f000
a0b00e 0dc0f0
0ace00 df000b
0f00d0 e0bc0a
sampleb. qoms (standard)
0000000011=2,0
0000001100
0000001100
0000010010
0001100000
0101000000
0010010000
0100100000
2000000000
0010000001
sample b.poms (standard)
q0000000000
00q00000000
0000q000000
000000q0000
00000000q00
0000000000q
0q000000000
000q0000000
00000q00000
0000000q000
000000000q0
sample c.oss (standard)
zxdxybzyz
zxdzxezxz
xxbyyxzzx
zybzzfxzy
cadccbcdc
cdbdcbdbb
xzezxdyyx
zxezybzyy
bddbcbdca

- One of the major hurdles that those doing research on carbohydrates in engineering schools are constantly struggling to overcome is the limited tools available to decipher sugar's role. As a solution, most researchers utilize lectins (sugar-binding proteins) isolated from plants or fungi, but lectins are large, weakly binding, and have limited specificity and range of sugars they can detect.
-In a new study published in ACS Chemical Biology, researchers from Professor Barbara Imperiali's group have developed a platform to address this shortcoming. "The problem with carbohydrate polymers is that their biosynthesis is not template-based," said Imperiali, lead author of the study and professor in the Department of Chemistry and Biology. "Biology, medicine and biotechnology have advanced thanks to technological advances in proteins and nucleic acids. The field of carbohydrates is very far behind and is desperately looking for tools." Identification of carbohydrate-binding proteins Biosynthetic carbohydrates require all linkages between individual sugar molecules to be made by specific enzymes, and there is no ready-made method to decipher the structure and sequence of complex carbohydrates.
-It is possible to generate antibodies against carbohydrates, but doing so is difficult and expensive, and produces molecules much larger than actually needed for research. An ideal resource in this field, plagued by limited mechanisms, is the discovery of binding proteins of limited size that recognize small chunks of carbohydrates to join structures using assemblages, or methods to detect and identify specific carbohydrates within complex structures.
==========================
memo 2212230530 my thought experiment oms storytelling
I have been studying number pile magic squares for a long time. Complex arrangements are like meeting carbohydrates. However, with the discovery of sample a.oms and sample b.qoms, I was able to come into contact with the details of the number pile and material pile.
As it suffers from a limited mechanism, the ideal resource in this field is assemblage, a binding protein of limited size that recognizes small chunks of a carbohydrate-like arrangement to combine in multiple steps into a structure using assemblages. The discovery of a constant or specific carbohydrate within a complex structure. .became a way to detect and identify array patterns. haha.
Samplea.oms (standard)
b0acfd 0000e0
000ac0 f00bde
0c0fab 000e0d
e00d0c 0b0fa0
f000e0 b0dac0
d0f000 cae0b0
0b000f 0ead0c
0deb00 ac000f
ced0ba 00f000
a0b00e 0dc0f0
0ace00 df000b
0f00d0 e0bc0a
sampleb. qoms (standard)
0000000011=2,0
0000001100
0000001100
0000010010
0001100000
0101000000
0010010000
0100100000
2000000000
0010000001
sample b.poms (standard)
q0000000000
00q00000000
0000q000000
000000q0000
00000000q00
0000000000q
0q000000000
000q0000000
00000q00000
0000000q000
000000000q0
sample c.oss (standard)
zxdxybzyz
zxdzxezxz
xxbyyxzzx
zybzzfxzy
cadccbcdc
cdbdcbdbb
xzezxdyyx
zxezybzyy
bddbcbdca



댓글